

PDF is an elegant little format. It does exactly what it says on the can, letting you display and exchange documents reliably, independent of software, hardware, or operating system.
But the portability comes at a cost. If you’re trying to do anything programmatically, PDFs aren’t exactly a friendly file format. They can consist of almost anything: unstructured data with different text encodings, embedded fonts, and images, making it challenging to extract data accurately and consistently. The format is designed more for presentation than data manipulation, so extracting content can be a massive headache, requiring specialized tools and approaches.
Luckily, there are ways around said headaches. Several libraries, tools, and techniques exist to get data out of PDFs with relative ease. Here, we’ll go through and show you how you can start to extract data from PDFs. The ones we’re going to cover today:
- Using language-specific libraries to pull content out of PDFs. In this case, the PDF.js library in JavaScript
- Using AI models to read and parse PDFs
- Using Retool to create an easy file uploader and reader and link the output to other components.
Let’s go!
PDF.js is the go-to library for this in the JavaScript ecosystem. (Check out pypdf for a similar library in the Python world or the pdf-reader gem in Ruby.)
We can use this library with node by installing the pdfjs-dist package:
1npm install pdfjs-distBe sure to install Node.js if you don’t already have it. Let’s get straight to the code:
1// ExtractPDF.js
2
3import fs from "fs";
4import { getDocument } from "pdfjs-dist/legacy/build/pdf.mjs";
5
6// Some PDFs need external cmaps.
7const CMAP_URL = "./node_modules/pdfjs-dist/cmaps/";
8const CMAP_PACKED = true;
9
10// Loading file from file system into typed array.
11const pdfPath = process.argv[2];
12const data = new Uint8Array(fs.readFileSync(pdfPath));
13
14// Load the PDF file.
15const loadingTask = getDocument({
16 data,
17 cMapUrl: CMAP_URL,
18 cMapPacked: CMAP_PACKED,
19});
20
21try {
22 const pdfDocument = await loadingTask.promise;
23 console.log("# PDF document loaded.");
24 // Get the first page.
25 const page = await pdfDocument.getPage(1);
26
27 // Extract the text content from the page
28 const textContent = await page.getTextContent();
29
30 // Concatenate and log the text items
31 const extractedText = textContent.items.map((item) => item.str).join(" ");
32 console.log(extractedText);
33} catch (reason) {
34 console.log(reason);
35}Let's break down the code into its main components.
First, we have our imports. We need the fs module and the getDocument function from the pdfjs-dist/legacy/build/pdf.mjs module. The fs module is a part of Node.js core and allows you to interact with the file system, such as reading files, as we’re doing here. The getDocument function is a part of the pdfjs-dist library to load the document into the library.
From there, we want to set up some character maps (CMAPs), which are needed for PDFs that contain text in fonts that use non-standard encodings. These constants specify the location of the CMAP files and whether they are packed.
Then, we’ll read the PDF file, which we feed through the command line (accessed via process.argv[2]). The function uses the fs.readFileSync method to read the file synchronously from the file system and stores the data in a Uint8Array.
This array is then ready to be processed using the getDocument function. We pass this function an object with our data and CMAPs. (We can probably get away without the CMAPs in this instance as we’re just extracting basic text, but we’ll give getDocument the option anyway.) The loading and processing of the PDF document is asynchronous, so we’ll use the await call. Once all the text is extracted, we’ll concatenate it and print it to the command line.
We can call this function with:
1node ExtractPDF.js file.pdfWe’re using the first page of Dickens’ classic A Tale of Two Cities as our test subject. Running this code with that page gives us:
A T A L E O F T W O C I T I E S Chapter 1 The Period It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity , it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair , we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way—in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only . There were a king with a large jaw and a queen with a plain face, on the throne of England;
And so on.
This is good and works, though it has some current limitations:
- The styling isn’t great. This isn’t an issue for most processing needs, but you might consider tidying up the text a little.
- You will need a lot more configuration once you get to anything more complicated.
- It’s limited to just processing a single PDF at a time. We can fix that by changing the code slightly to take a directory of PDFs as input and then iterate through the files in that directory.
- It’s just a CLI tool as-is. This is fine for analysts who like typing commands into computers, but for the point-and-click brigade, it’s less optimal.
Let’s fix this last issue by adding a simple web interface to our PDF extraction function. Create a file called server.js and add this code:
1import express from "express";
2import multer from "multer";
3import fs from "fs";
4import { getDocument } from "pdfjs-dist/legacy/build/pdf.mjs";
5const upload = multer({ dest: "uploads/" });
6
7const app = express();
8const port = 3001;
9
10// Serve static files from the "public" directory
11app.use(express.static("public"));
12
13// Route to upload a PDF and extract text
14app.post("/upload", upload.single("pdf"), async (req, res) => {
15 try {
16 const data = new Uint8Array(fs.readFileSync(req.file.path));
17 const loadingTask = getDocument({ data });
18 const pdfDocument = await loadingTask.promise;
19 console.log("# PDF document loaded.");
20
21 const page = await pdfDocument.getPage(1);
22 const textContent = await page.getTextContent();
23 const extractedText = textContent.items.map((item) => item.str).join(" ");
24
25 res.send({ extractedText });
26 } catch (error) {
27 console.error(error);
28 res.status(500).send("Error processing PDF");
29 } finally {
30 // Clean up uploaded file
31 fs.unlinkSync(req.file.path);
32 }
33});
34
35app.listen(port, () => console.log(`Listening on port ${port}`));
36
37All we’ve done here is wrap our PDF extraction function in an Express web server backend. When someone calls the /upload endpoint, they’ll run the extraction on whatever document they have uploaded. Of course, they need to upload something first. The multer library helps here, making uploading documents to a site easy.
We need a frontend so a user can add a document and see the results. Add a directory called ‘public’ and then an index.html file within it:
1<!DOCTYPE html>
2<html lang="en">
3 <head>
4 <meta charset="UTF-8" />
5 <meta name="viewport" content="width=device-width, initial-scale=1.0" />
6 <title>PDF Text Extractor</title>
7 </head>
8 <body>
9 <h1>Upload a PDF to Extract Text</h1>
10 <form id="upload-form" enctype="multipart/form-data">
11 <input type="file" name="pdf" required />
12 <button type="submit">Extract Text</button>
13 </form>
14 <textarea
15 id="result"
16 rows="10"
17 cols="50"
18 placeholder="Extracted text will appear here..."
19 ></textarea>
20
21 <script>
22 document
23 .getElementById("upload-form")
24 .addEventListener("submit", async function (e) {
25 e.preventDefault();
26 const formData = new FormData(this);
27 const response = await fetch("/upload", {
28 method: "POST",
29 body: formData,
30 });
31 const data = await response.json();
32 document.getElementById("result").value = data.extractedText;
33 });
34 </script>
35 </body>
36</html>This creates a few UI components—a file uploader, a button, and a text field—we’ll need to help manipulate our document, and then it sends the document to that /upload endpoint. We can start our server with:
1node server.jsThen we can hop on over to localhost:3001 and do some extraction:
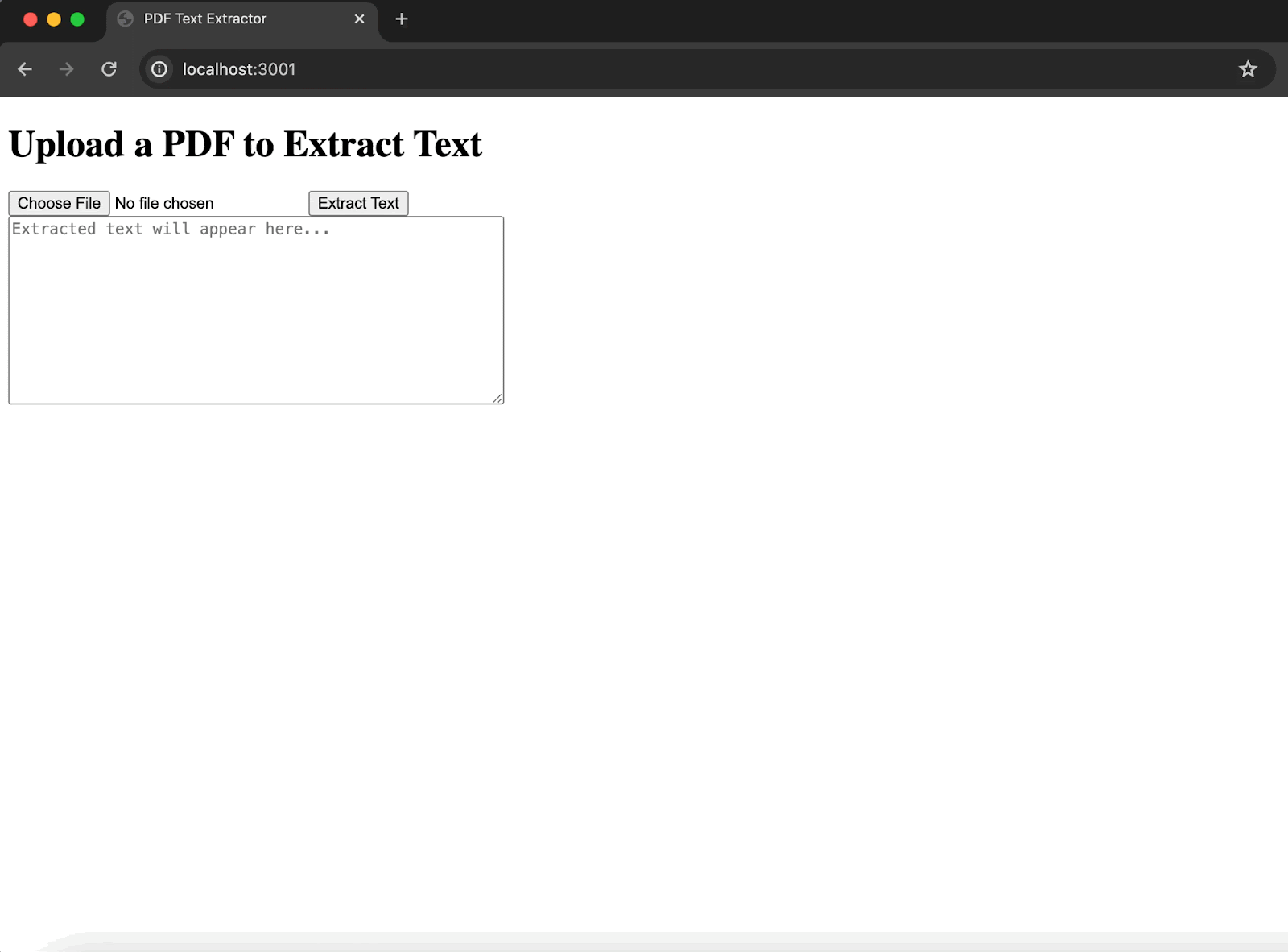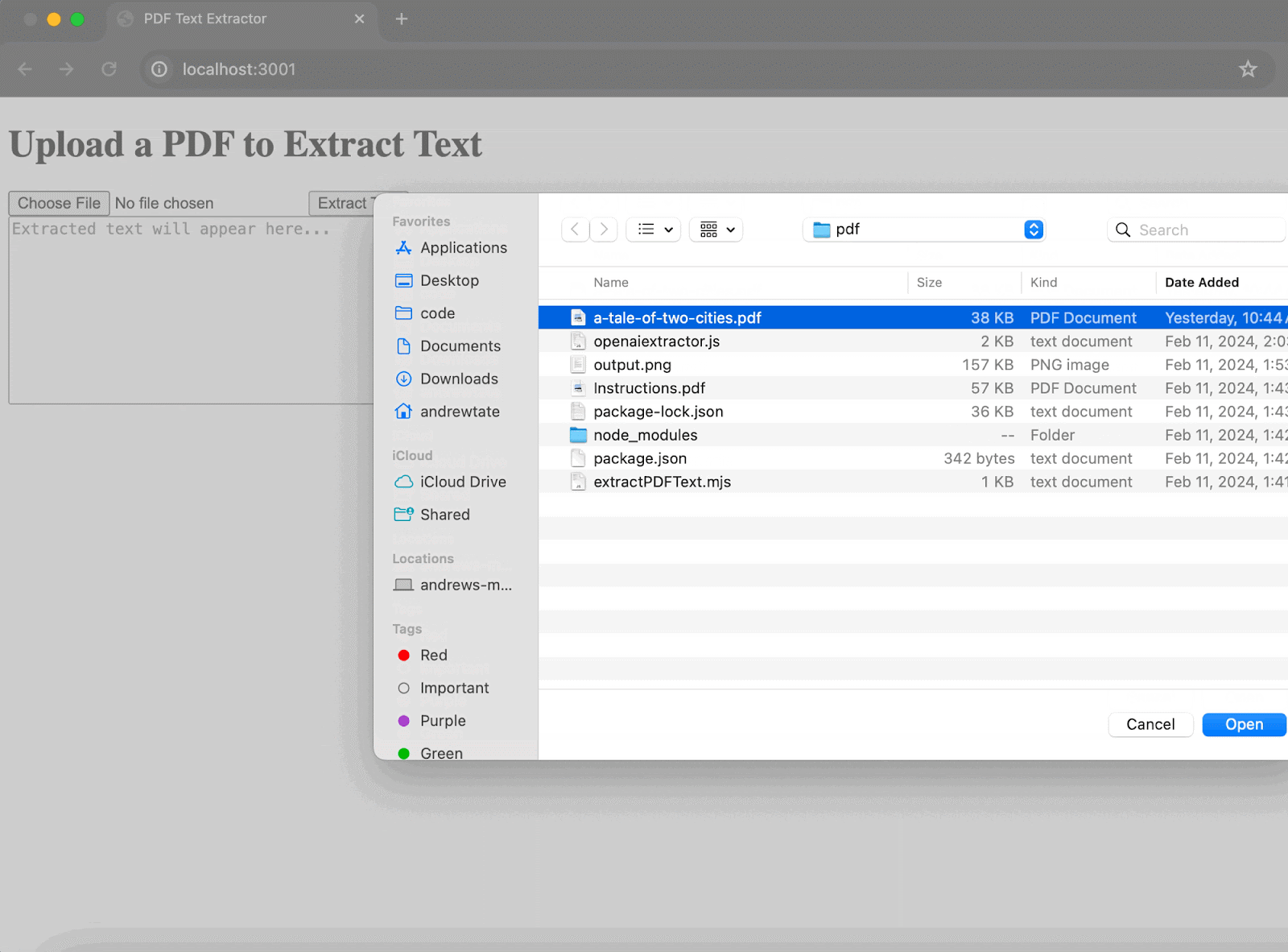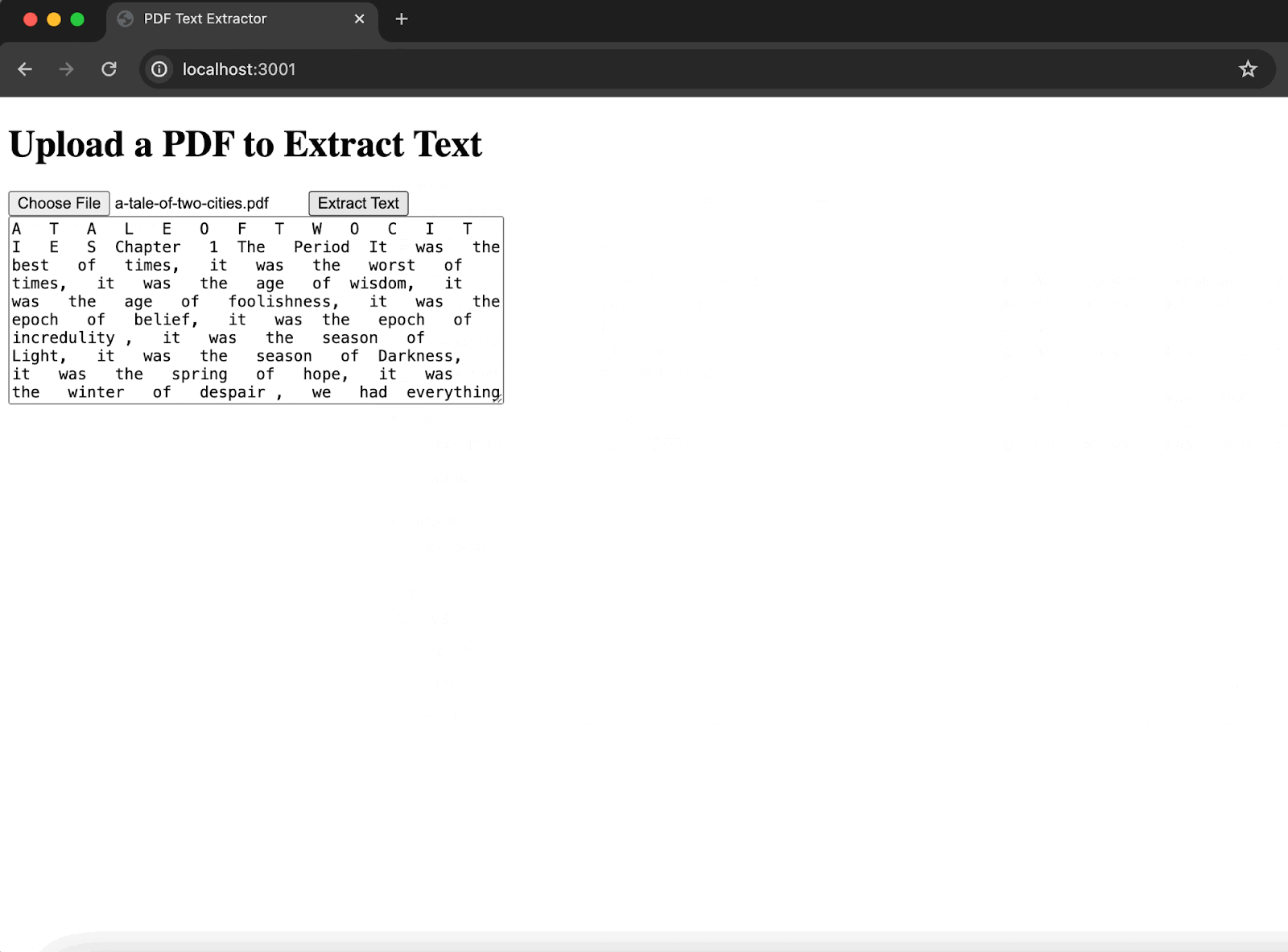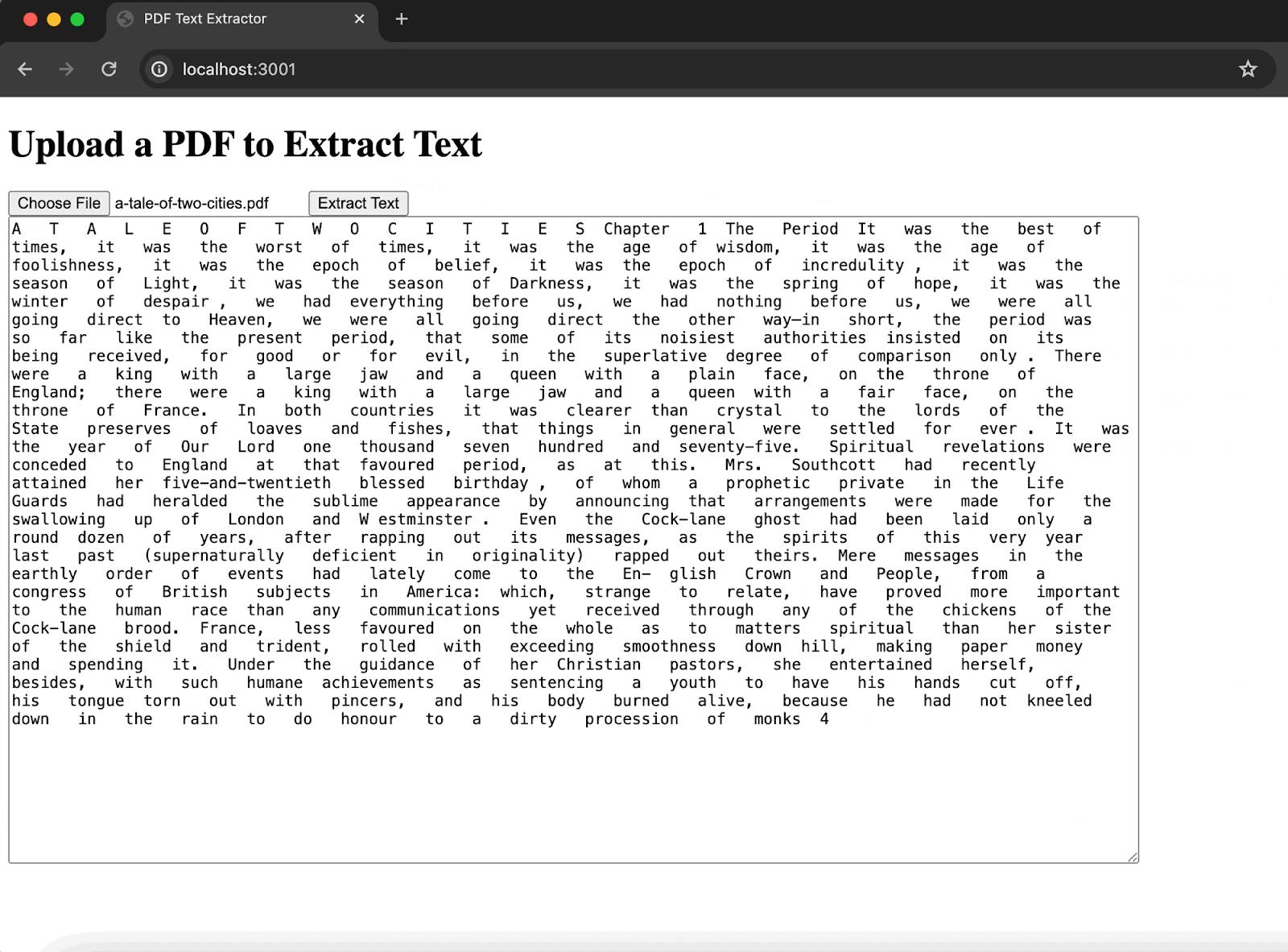
With that, we have a PDF extraction interface to start using. This is a good option, though again, it comes with trade-offs:
- Sorry, we’re still not styling. You should probably make the text look better on the screen.
- When you deploy this, you’ll have to think about ways to store uploaded documents for processing, such as in an S3 bucket.
But if you need a simple PDF extraction tool, you now have it.
Coding up a simple extraction tool is cool and all, but if you are not using AI in 2024, can you even call yourself a developer? (Well, of course you can—but extracting unstructured data is a pretty popular AI use case.)
Let’s fix the above simple solution by complicating it and throwing GPT into the mix.
1import OpenAI from "openai";
2import dotenv from "dotenv";
3import fs from "fs";
4
5dotenv.config();
6
7const openai = new OpenAI(process.env.OPENAI_API_KEY);
8
9const instruction = `You are a PDF extractor. please extract whatever the user asks from the page.`;
10
11const user_request = `Can you extract everything from this page please?`;
12
13async function main() {
14 console.log("Creating a PDF file...");
15const pdfPath = process.argv[2];
16 const file = await openai.files.create({
17 file: fs.createReadStream(pdfPath),
18 purpose: "assistants",
19 });
20
21 // Add the file to the assistant
22 console.log(file);
23 console.log("Creating an assistant...");
24 const assistant = await openai.beta.assistants.create({
25 instructions: instruction,
26 model: "gpt-4-turbo-preview",
27 tools: [{ type: "retrieval" }],
28 file_ids: [file.id],
29 });
30
31 console.log(assistant);
32 console.log("Creating a thread...");
33 const thread = await openai.beta.threads.create();
34
35 console.log(thread);
36 console.log("Adding a message...");
37 const message = await openai.beta.threads.messages.create(thread.id, {
38 role: "user",
39 content: user_request,
40 file_ids: [file.id],
41 });
42
43 console.log(message);
44
45 const run = await openai.beta.threads.runs.create(thread.id, {
46 assistant_id: assistant.id,
47 });
48
49 console.log(run);
50
51 while (true) {
52 const current_run = await openai.beta.threads.runs.retrieve(
53 thread.id,
54 run.id
55 );
56 if (current_run.status === "completed") {
57 const threadMessages = await openai.beta.threads.messages.list(thread.id);
58
59 console.log(threadMessages);
60
61 for (let i = 0; i < threadMessages.data.length; i++) {
62 const message = threadMessages.data[i];
63
64 if (message.role === "assistant") {
65 const retrievedMessage = await openai.beta.threads.messages.retrieve(
66 thread.id,
67 message.id
68 );
69 console.log(retrievedMessage.content);
70 }
71 }
72 break;
73 }
74 //pause for 10 seconds
75 await new Promise((resolve) => setTimeout(resolve, 10000));
76 }
77}
78
79main();
80Here, we’re using a part of the OpenAI API called Assistants. Assistants have “instructions and can leverage models, tools, and knowledge to respond to user queries.” If you’ve used the code interpreter in ChatGPT, you’ve been using an Assistant.
OpenAI is rolling out Assistants in beta. Here, we’re using the “retrieval” Assistant that lets you use external documentation as an input to the model to retrieve information. The flow in the code above is:
- Add a file to OpenAI and label it to be used with an Assistant.
- Create an Assistant with the
gpt-4-turbo-previewmodel, theretrievaltool, and the uploaded document. You also need to give the Assistant instructions. Here, we’re telling the Assistant it’s a PDF extractor, but you could give it more specific instructions. (See our point about prompt engineering below.) - Create a thread to chat with the Assistant and add a message to that thread with what you specifically want the Assistant to do. (Can you extract everything from this page please?)
- Set the Assistant running, then poll the retrieve runs endpoint to see when it has completed (the run doesn’t happen immediately–it’s queued. Here, we’re polling it every ten seconds until the status becomes “completed”).
- Then, extract the message from the Assistant.
That final step here gives us:
Here is the extracted text from the page you requested:\n' +
'\n' +
'**Chapter 1\n' +
'The Period**\n' +
'\n' +
'It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way—in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.\n'
And so on.
What are the problems going to be here?
Cost can be an issue. Every time you request the OpenAI API, you incur a cost. This is small, but if you use this PDF extraction as part of a more extensive process, costs can creep up. Added to that, costs are also determined by what’s returned. Extracting much data or text from a PDF can incur more significant costs.
Another issue, which is essential if you’re uploading sensitive documents, is that you’re sending that data to OpenAI servers, where it may be used for training purposes. If you have sensitive or confidential data—for instance, you need to extract data from medical records—this can be a severe liability. Read the fine print and act accordingly.
The bigger problem with using AI in general here is that it’s sensitive to prompt engineering. Prompt engineering is the influence your prompt has on the output. Here, we have two prompts, one to create the Assistant and another to ask the Assistant to help:
1const instruction = `You are a PDF extractor. please extract whatever the user asks from the page.`;
2
3const user_request = `Can you extract everything from this page please?`;Here, it did that. But it also added a little coda at the end:
'This page begins with the famous opening line of "A Tale of Two Cities" by Charles Dickens, describing the contradictory nature of the period leading up to the French Revolution, and provides a vivid picture of the conditions in England and France during the late 18th century.'
This is a helpful literary analysis, but not what we asked for. AI can’t help but be helpful—which makes it a good option if you don’t want the actual data or text from the PDF, but want the insight from that data/text. In that case, you can use AI to extract more information and meaning than you might be able to with a more straightforward tool.
If you need to build PDF extraction into your tooling, Retool can give you a straightforward way to do this with no code (unless you want to customize something), deployments, or S3 buckets for storage—just the tool you need.
To build this, we’ll use a component of Retool AI, the Convert document to text action. Within your app builder, you can hit the code menu button on the left-hand side and then add a new query. Name the query, choose “Retool AI” as the Resource, then “Convert document to text” as the Action.
Finally, create a file upload component and add that as the file source:
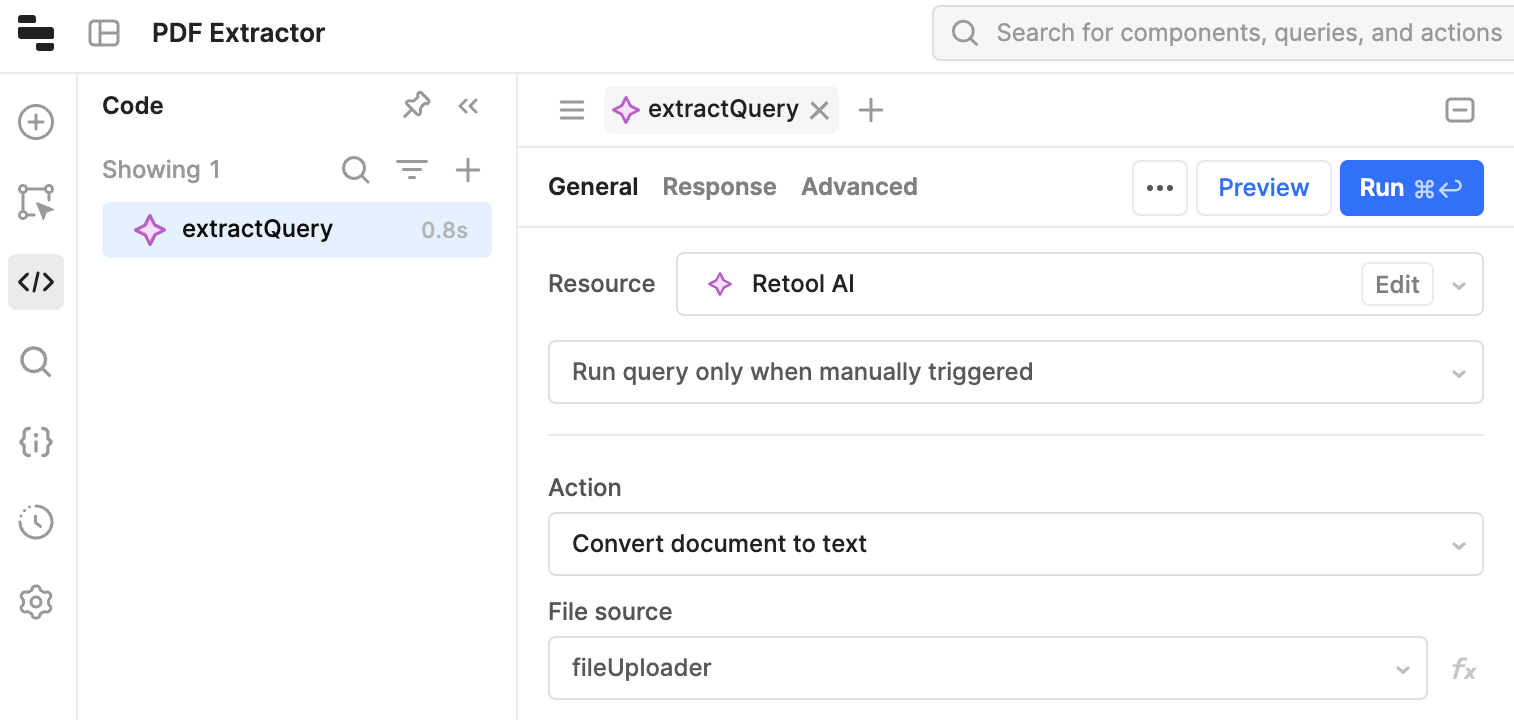
That’s it for the extraction. We could run it now, and it will work. But we want to build out the UI to mimic what we built above. To do so, we’ll add a button to trigger the query and a textbox to show the text. Then we can extract when we hit Extract:
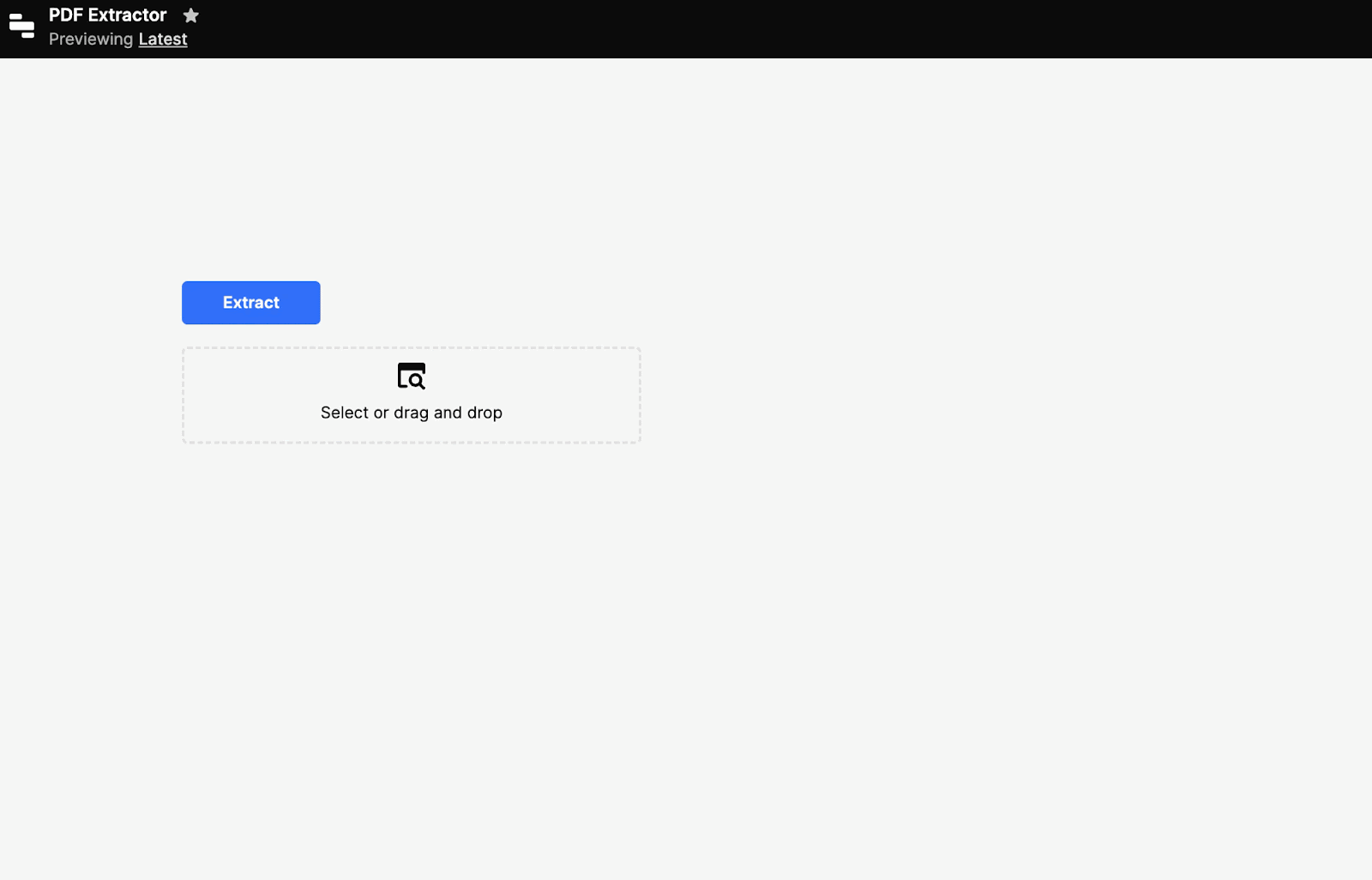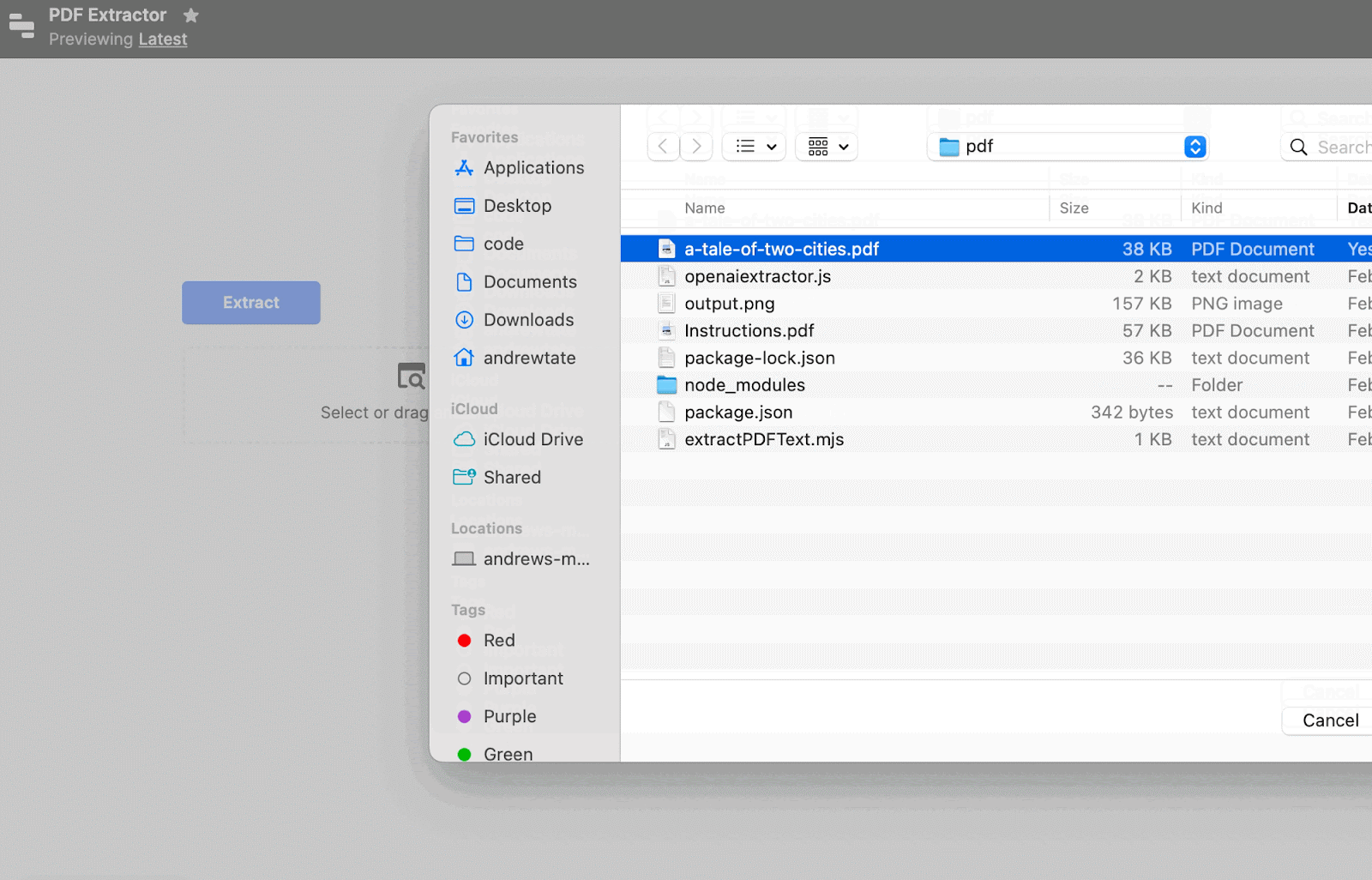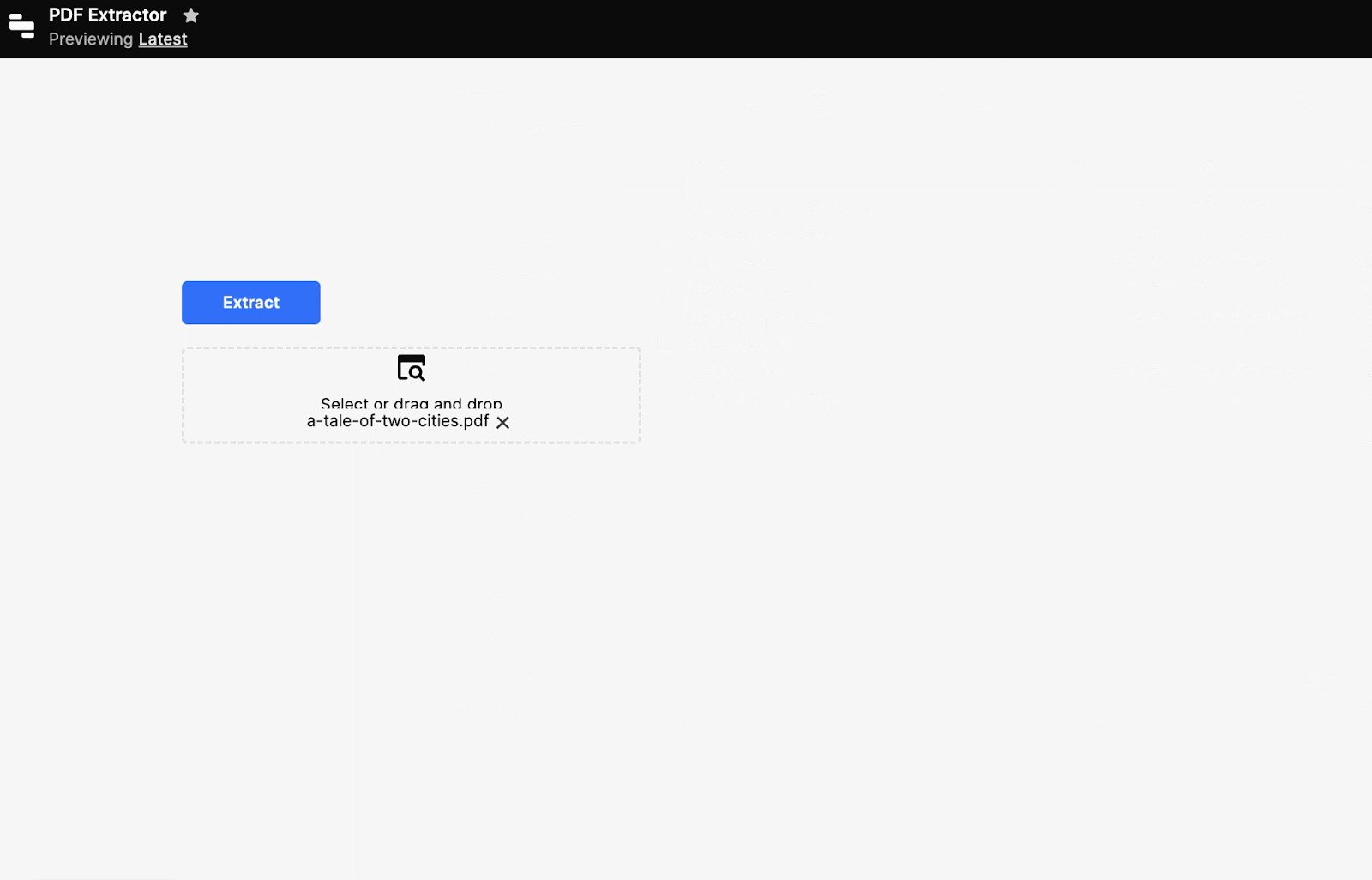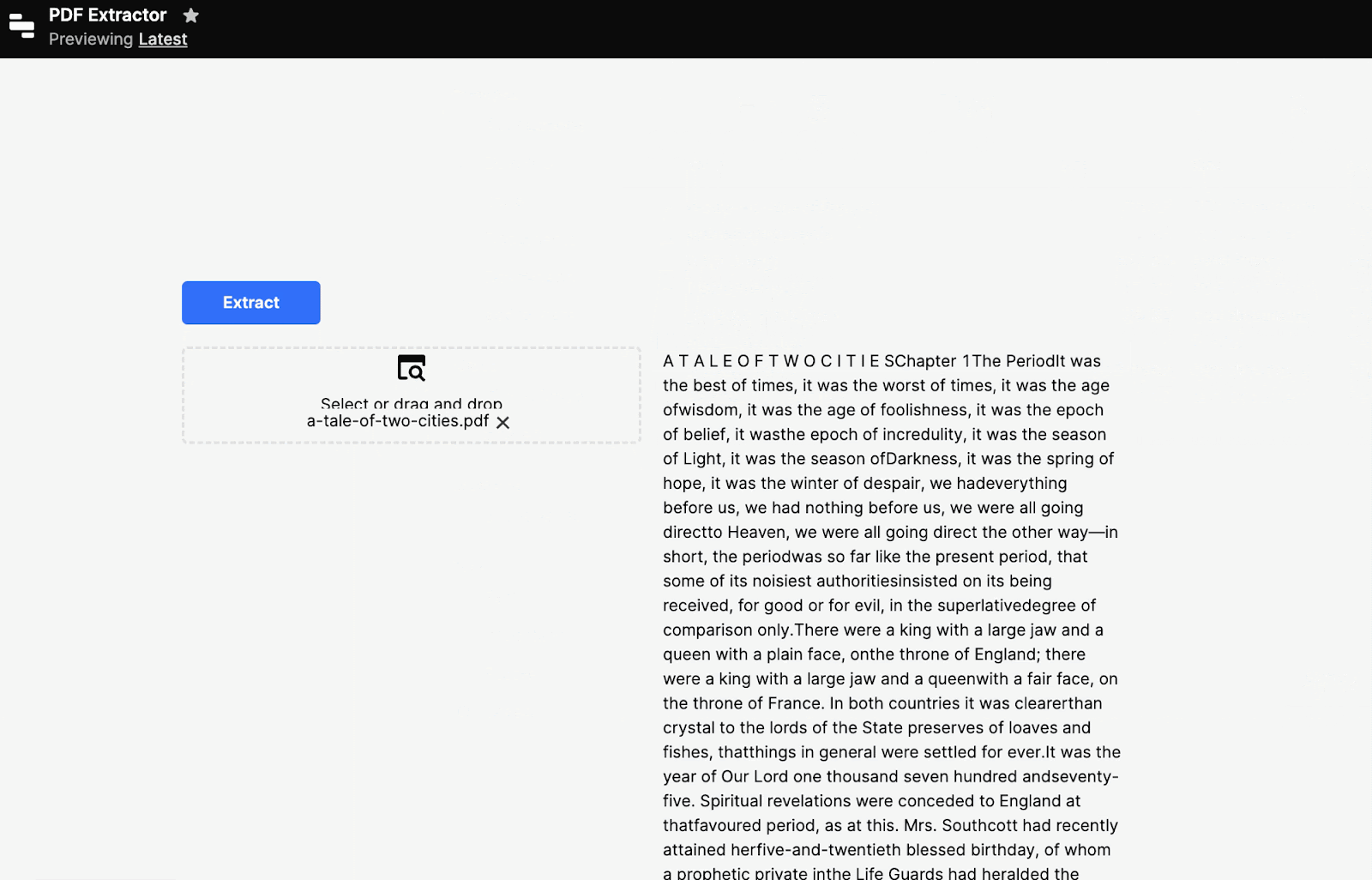
Done. The styling of the extracted text is nicer than our homegrown version above, as well.
Importantly, though this is part of the Retool AI toolset, AI isn’t used in this part of the process—neither this text nor the original document has been sent to an AI model. The Convert document to text action is part of Retool AI because it’s a starting point for further processing of documents by AI. For instance, from here, you could summarize the text or ask the AI questions as part of the prompt: “Was it the best of times?”
PDFs have always been locked away, but with these options, you can start to access all the text and data in your PDFs. Depending on what you need from the extracted text, you have multiple options. Libraries give you great control over what you extract, but you have to do a lot of building. AI gives you insight but at the cost of needing to know what the model wants. Retool gives you a quick way to start extracting text and then using it within an AI pipeline for further insight.
You can learn more about Retool AI and immediately get started with PDF extraction and AI workflows by signing up for Retool today.

