

This post is a guest post from Anthony Accomazzo, co-founder of the integration platform Sequin.
The other day the Sequin team and I ran into an all-too-familiar situation: we needed to write some code that I knew we’d written before, but we couldn’t find it.
The module had long been deleted, and was lingering somewhere in our git history. We didn’t remember what the module was called or any other identifying details about the implementation or the commit.
After scraping my mind and scraping through git reflog, we eventually found it. But we realized that simple text search through our Git history was limiting.
It dawned on us that we wanted to perform not a literal string search but a semantic search.
This seemed like the kind of problem that embeddings were designed to solve. So, having identified a problem in need of a solution, we set out to build the tool we’d need for next time.
In this post, I’ll walk you through how to build an embeddings search tool for your GitHub PRs, issues, and commits. With embeddings, you're no longer restricted to simple string comparison—you can build a search function that does advanced semantic comparison between your search query and your data.
In the process, we'll make use of some neat tools and concepts including:
- Retool Workflows
- Retool apps
- OpenAI's API
- Embeddings
- Sequin
In addition to the search tool demonstrated in this post, you can build on this foundation to do cluster analysis. For example, you can determine how many commits and/or PRs in the last month were related to bug fixes versus new features. (I'll touch on that at the end of this post.)
Let’s get started.
An embedding is a vector representation of data. A vector representation is a series of floats, like this:
1[-0.016741209, 0.019078454, 0.017176045, -0.028046958, ...]
2Embeddings help capture the relatedness of text, images, video, or other data. With that relatedness, you can search, cluster, and classify data.
Embeddings enable an advanced search method of our GitHub records. First, we can generate embeddings for all pull requests, issues, etc. Then, we can perform a query using another embedding. The user will type in a query, such as add a serializer and deserializer for storing objects in the database. We can take that query, turn it into an embedding, and compare its relatedness to the embeddings of all the notes.
To generate embeddings, you'll want to rely on a third-party vendor. You can use APIs like OpenAI's to generate them.
To generate embeddings for your data, you'll want your data in a database that supports vectors. Fortunately, Postgres supports vectors via the pgvector extension.
You can import your GitHub data into Postgres using a service like Sequin. Sequin runs a real-time sync process that pulls data from external APIs into your Postgres database. Any time a record changes in the API, that change is synced to your database. Likewise, Sequin intercepts mutations you make to records in your database, and applies them to the API before committing them to your database.
With your GitHub data syncing to Postgres, you can easily build embeddings-powered apps and workflows with Retool.
Your application will revolve around a Postgres database. Sequin will sync GitHub commits and PRs to your database. Using a Retool Workflow, you'll generate OpenAI embeddings for each of the GitHub objects you want to perform searches against. (This post assumes you're already set up with accounts on Retool, Sequin, and OpenAI—if not, click those links to get started with each!).
To perform a search, the user will type in a query, such as "embed Elixir struct into Postgres jsonb." Then, you can take that query, turn it into an embedding, and compare its relatedness to the embeddings of all the commit messages and PR bodies.
You'll also need to set up a workflow to ensure new or updated PRs and commits that Sequin syncs to your database have their embeddings generated as well.
The architecture will look like this:
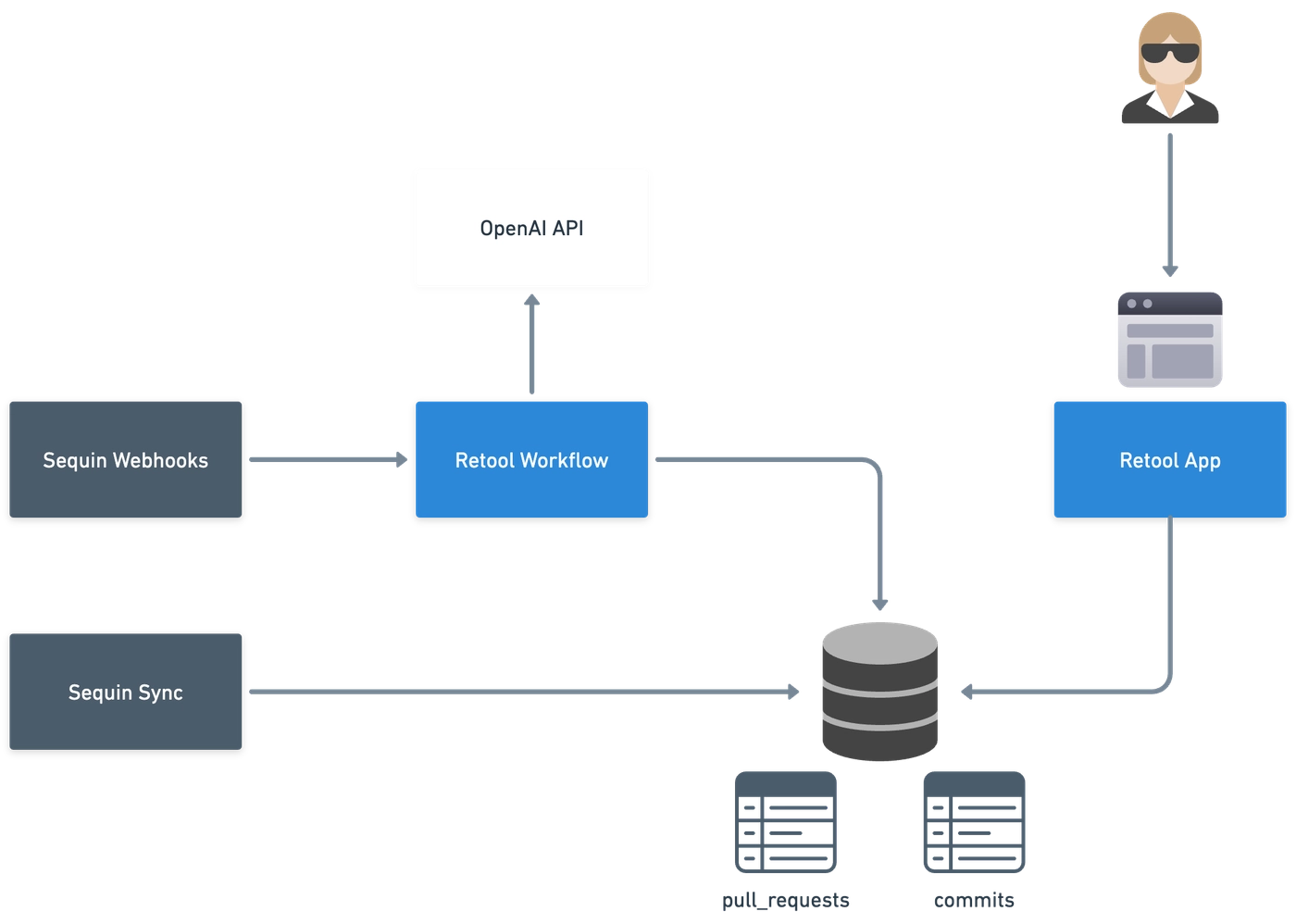
On the left, Sequin will continuously sync GitHub data to your database. This includes things like the titles and bodies of pull requests and the tags and comments in Issues. It will also fire off webhooks that you can use to trigger a Retool Workflow, which will update the embeddings for new and updated records.
The right hand side of the diagram shows the user-facing Retool app that will perform search queries against the database.
To generate embeddings, you'll want to rely on a third-party tools like word2vec or services like Vertex AI or OpenAI. For our purposes, we’ll use Open AI’s APIs to generate them.
To prepare your database, first add the pg_vector extension:
1create extension vector;
2Note: pg_vector is included in most of the latest distributions of Postgres.
If you're on AWS RDS, be sure to upgrade to Postgres 15.2+ to get access to the vector extension.
Create a separate schema, github_embedding, for your embedding data. In your queries, you'll join your embedding tables to your GitHub tables.
Here's an example of creating an embedding table for GitHub commits:
1create table github_embedding.commit (
2 id text references github.commit(id) on delete cascade,
3 embedding vector(1536) not null
4)
5In this post, we’ll be using OpenAI's text-embedding-ada-002 model, which generates embeddings with 1536 dimensions—hence the 1536 parameter above.
Note: You can mix and match fields from different tables to generate embeddings. To start, you can keep it simple and generate embeddings that correspond to a single GitHub object. For most objects, you'll probably choose to create an embedding for just one or two fields. For example, you don't need to create an embedding for the whole Pull Request object, just the title and body fields. You can concatenate the two fields together into a newline-separated string, and generate the embedding on that.
In the future, you can blend more fields or objects together to let you build on your data in novel ways.
You'll start by setting up your app to generate embeddings for GitHub records as they're inserted or updated. Then, I'll show you how to backfill embeddings for your existing records.
You have two options for finding out about new or updated GitHub records in your database.
You can use Postgres' listen/notify protocol. It's fast to get started with and works great. But notify events are ephemeral, so delivery is at-most-once. That means there's a risk of missing notifications, and therefore potential holes in your data.
Along with a sync to Postgres, Sequin provisions an event stream for you. Sequin will publish events to a serverless Kafka stream associated with your sync. Sequin will publish events like "GitHub Pull Request deleted" or "GitHub Commit upserted."
You can configure connectors to this Kafka stream. One of the connectors is HTTP, which POSTs events to an endpoint you choose. We can use the HTTP connector to have events sent to a webhook endpoint over on Retool. That webhook endpoint can trigger a workflow, which we can use to update the embeddings table. Notably, unlike listen/notify, the Kafka stream is durable and the HTTP connector will retry on failure, meaning we can get at-least-once delivery.
Let's setup the workflow on Retool and configure it to receive webhooks.
First, over on Retool, create a new Workflow. In the startTrigger block, click "Edit triggers" and then toggle on "Webhook":
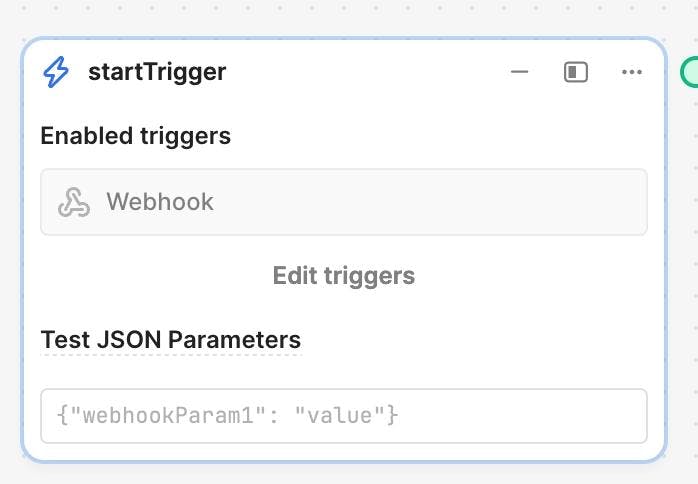
Selecting the "Webhook" toggle on the left rail will expand a drawer that reveals the endpoint URL for this Workflow. Copy that endpoint:
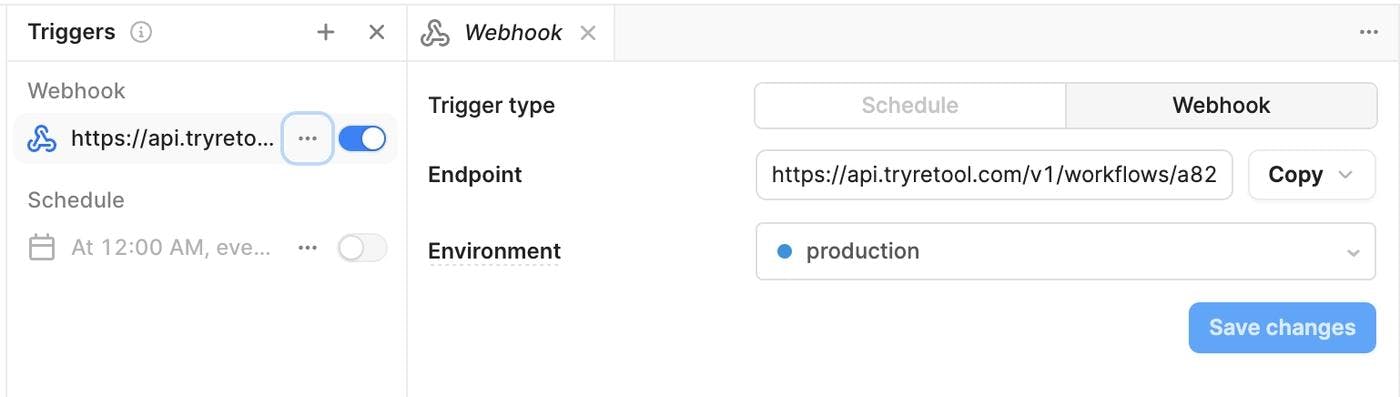
Before leaving Retool, save your changes and click the Deploy button to ensure the Webhook endpoint is running.
Then, over on Sequin, configure the "HTTP Connector" for your GitHub sync. For the destination "HTTP URL," enter your Workflow's webhook endpoint:
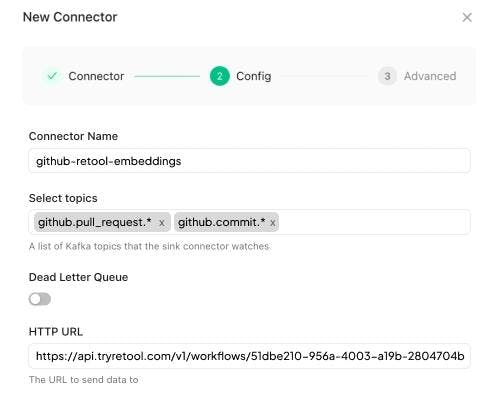
Click "Save." At this point, Sequin will send webhooks to your Retool Workflow every time it captures an insert or update to a GitHub pull request or commit. Make some changes over in GitHub, and you'll see those events kick off runs in your Retool workflow:

Now that Sequin is sending your workflow webhooks, you can compose a step in your workflow that takes the event and generates an embedding for the associated record. Last, you can create a step that upserts the embedding into your database.
To do so, add a new block to your Retool Workflow. This block will be a Resource Query to OpenAI. Configure your block like this:
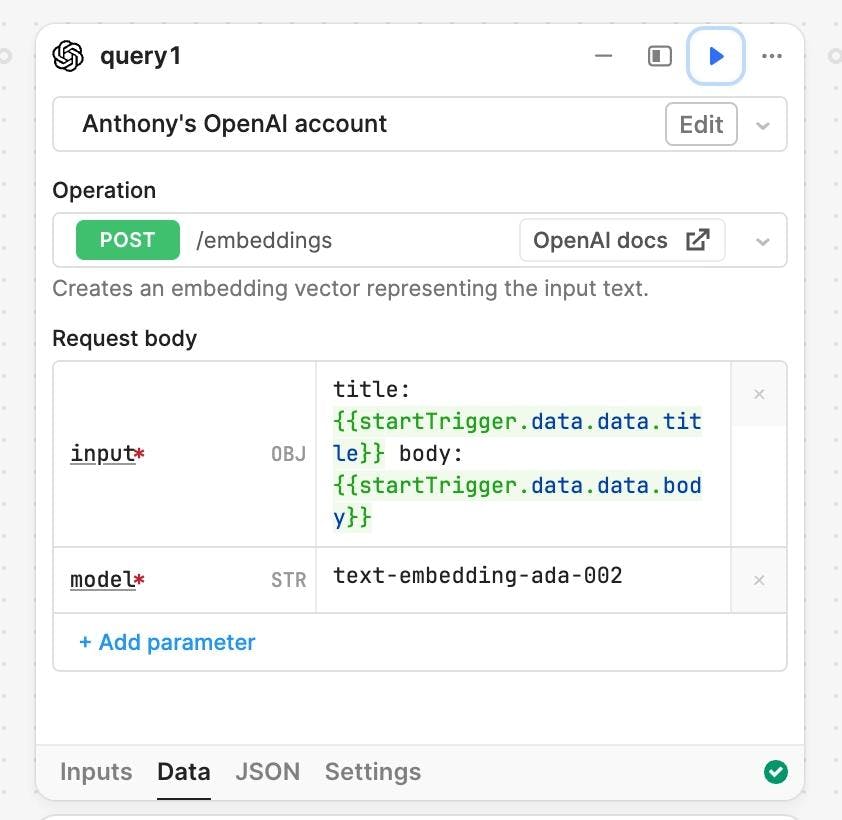
For Operation, select POST /embeddings. For the request body, set the input to the strings you want to generate the embeddings off of. In this example, we're generating embeddings for a pull request, and using its title and body.
For the model, use OpenAI's text-embedding-ada-002.
Press the "Play" icon and verify that your request works. You should see a JSON result from OpenAI that contains a list of a bunch of vectors.
Now that you have the embeddings, you can upsert them into your embedding table (see the create table statement above). I recommend you use Retool's GUI mode to compose the upsert query. Here's how to configure your upsert:
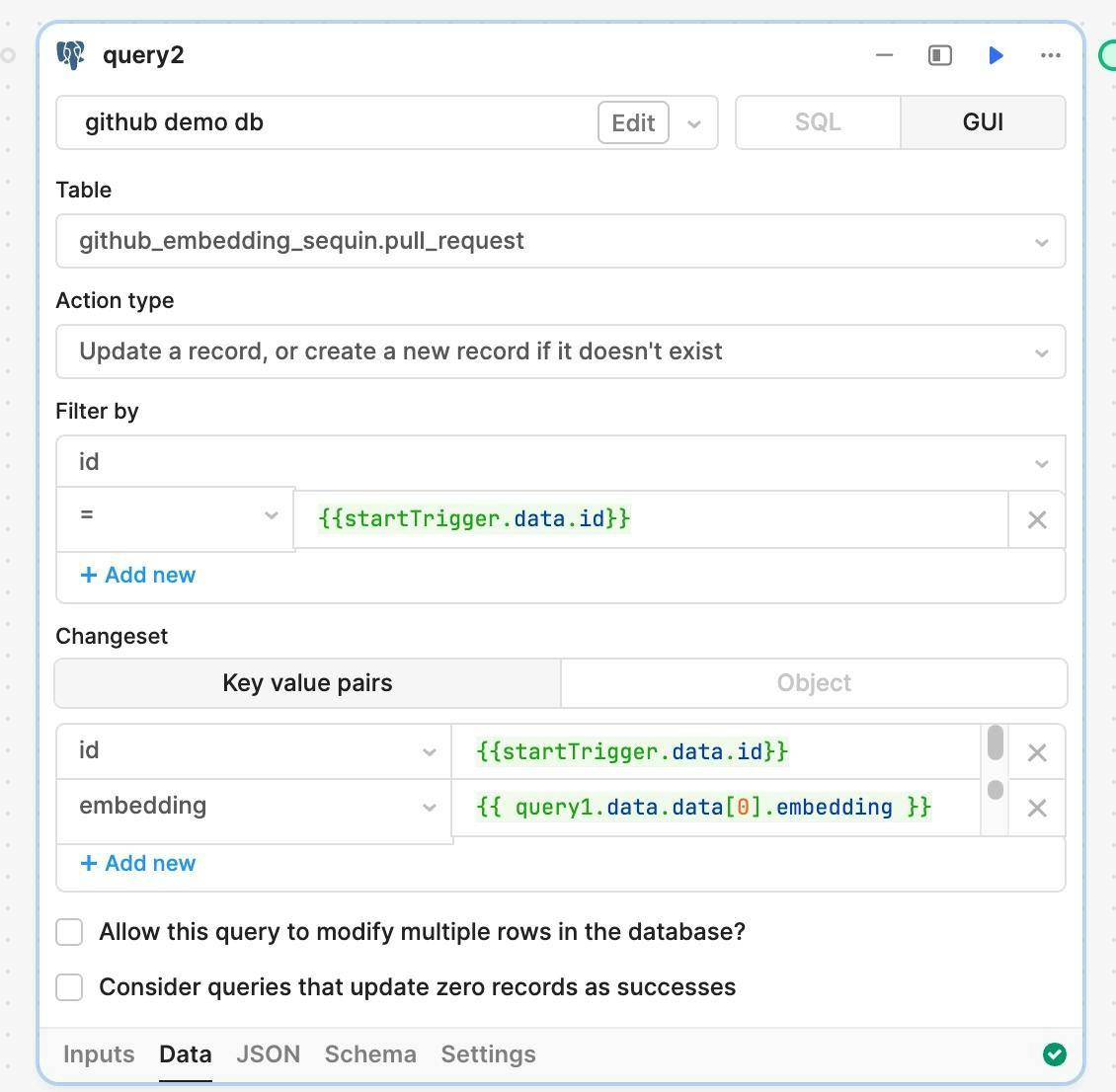
Be sure you select the right upsert "Action type," as shown above. You'll use startTrigger.data.id for the id column and query1.data.data[0].embedding for the embedding column (assuming you left your OpenAI query to the default query1).
At this point, you're ready to test things end to end. You can start by using a test event.
- In "Run history," select an event then select
startTrigger. - Click the "Data" tab.
- Scroll down to the bottom and you'll see "Use as example JSON."
- Click that.
Now, you should see "Test JSON parameters" populated for your startTrigger.
With test JSON parameters populated, you can step through each block:
- First, run the query to OpenAI and verify you get back a list of embeddings.
- Next, run your upsert.
- Assuming that succeeds, check your database and verify a row was indeed inserted.
Note: Embeddings are difficult to "validate" just by looking at them—you can accidentally send OpenAI a meaningless blank string, and it will still return a list of vectors. So be sure to validate that all the variables in your query are properly populated. With test data in place, you can click on variables and Retool will display a popover of the value of the variable.
Now, deploy your Retool workflow. At this point, when a GitHub record is inserted or updated, your workflow will get triggered and populate the associated embedding record. Try it! Head over to GitHub and open or edit a PR. Just a few seconds afterwards, you should see the run get triggered over in Retool.
With your listener in place, the next step is to backfill all the records with null values for embedding in the database.
You have two primary options for backfilling the embedding column:
You can write a one-off batch job that paginates through your table and kicks off API calls to fetch the embeddings for each record.
You can paginate through each table like this:
1select id, body, title
2 from github.pull_request
3 order by id asc
4 limit 1000
5 offset 0;
6Note: Normally a pagination strategy like this wouldn't be safe unless IDs were auto-incrementing. But this will work fine in all situations, because we don't care if we miss records that are inserted mid-pagination—those are being handled by our event handler above!
For each record you grab from the database, you can run through the same pipeline: fetch the embeddings, then upsert into the database.
This would normally mean creating a different workflow inside or outside of Retool, but you can have Sequin perform the backfill for you.
Alternatively, you can have Sequin do the record pagination and collection part for you. This will let you use your existing event handling code to backfill your table.
You can kick off a backfill of your events stream via the Sequin console. Sequin will paginate your Postgres tables and fill your stream with events that have the same shape as upsert events:
1{ "id": "1245638131", "collection": "commit", { "data": [ … ] } }
2To kick-off the backfill, Sequin will ask you which topic to publish these events to. We recommend using a distinct topic for these events, such as github.backfills.pull_request_embeddings—so before kicking off the backfill, be sure to update your Webhook sink in the Sequin console to subscribe to the topic. That will ensure that events published to this topic get sent to your Retool workflow.
After the backfill has completed, you'll have embeddings for all your desired GitHub objects!
With your embeddings set up in Postgres, you're ready to create a mechanism for querying them.
Supabase has a great post on embeddings in Postgres. I've adapted their similarity query below. You can use the cosine distance operator (<=>) provided by pg_vector to determine similarity. Here's a query that grabs a list of pull_requests over a match_threshold, ordered by most similar to least similar:
1select
2 pull_request.id,
3 pull_request.title,
4 pull_request.body,
5 1 - (embedding_pull_request.embedding <=> {{searchEmbedding.value}}) as similarity
6from github_sequin.pull_request as pull_request
7join github_embedding_sequin.pull_request as embedding_pull_request on pull_request.id = embedding_pull_request.id
8-- match threshold set to 0.75, you can change it
9where 1 - (embedding_pull_request.embedding <=> {{searchEmbedding.value}}) > 0.75
10order by similarity desc
11-- match count set to 5, you can change it
12limit 5;
13With your data model and search function squared away, you can build your search tool. It should have a table for results and a search bar.
Here’s a simple example of this tool, demonstrating a search for pull requests that mention "serialize and deserialize structs into jsonb ecto":
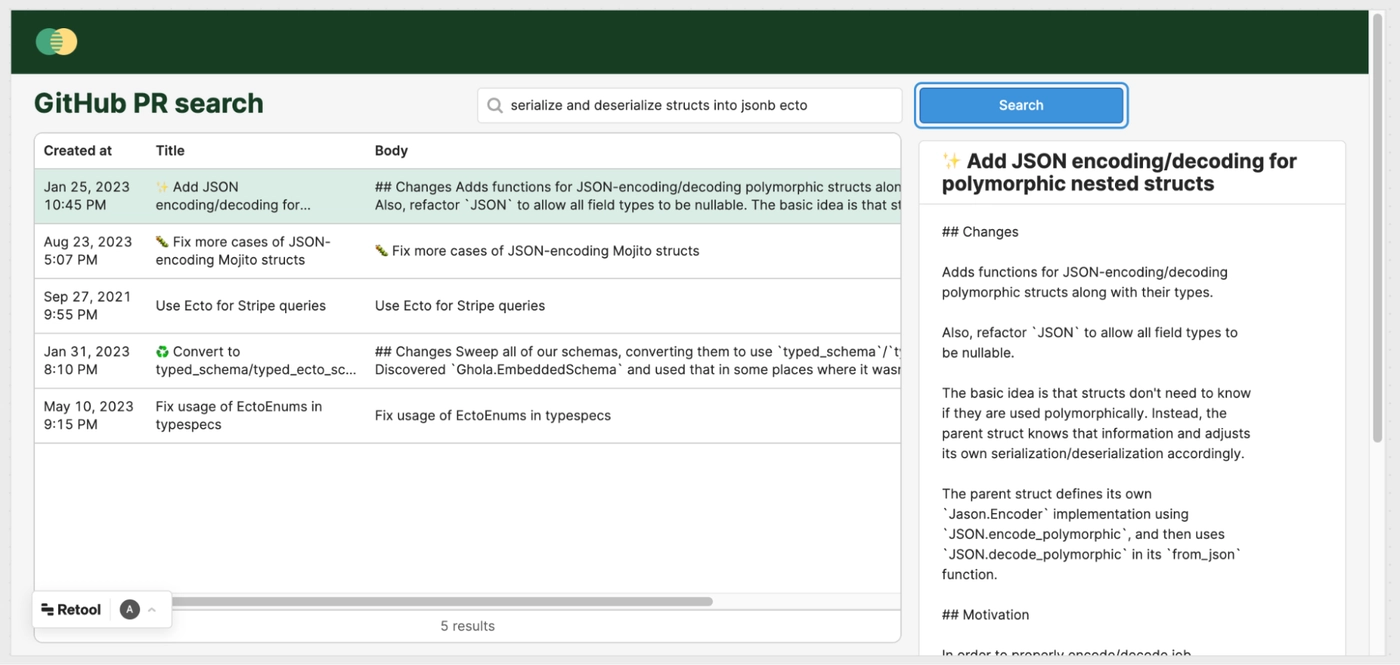
On the left, we see a descending list of the top five PRs that matched, sorted by similarity. On the right is a preview of the PR that we selected.
Note that this is not a literal string match. The search refers to the "serialize and deserialize errors," but the PR contains serializes/deserializes. The PR also doesn't mention jsonb, just JSON.
Because of embeddings, we found the exact PR we were looking for, and with only a vague idea of what we were looking for—nice!
To build a tool like this, drop in a basic table, a search bar, and a search button. Then, you'll compose your queries and variables. Here will be the flow:
- Users can enter a search query into the app and press "Search."
- Clicking "Search" will fire off
getQueryEmbedding(below), using OpenAI to convert the search input into an embedding. - When
getQueryEmbeddingreturns, it will set the value of the variablequeryEmbedding(below). - When the variable of
queryEmbeddingchanges, the Postgres querysearchPRs(below) runs. - Finally,
searchPRsdoes a similarity match between the embedding in the search query and the embeddings for all your GitHub pull requests stored in your database. It returns the most similar, rendering them in the table for your user to see.
Starting from the database and working up:
First, create a new variable, queryEmbedding, for storing the embedding of the search query.
Then create a new Postgres query called searchPRs. The body of the query will look like this:
1select
2 pull_request.id,
3 pull_request.created_at,
4 pull_request.title,
5 coalesce(nullif(pull_request.body, ''), pull_request.title) as body,
6 1 - (embedding_pull_request.embedding <=> {{queryEmbedding.value}}::vector) as similarity
7from github_sequin.pull_request as pull_request
8join github_embedding_sequin.pull_request as embedding_pull_request on pull_request.id = embedding_pull_request.id
9-- match threshold set to 0.75, you can change it
10where 1 - (embedding_pull_request.embedding <=> {{queryEmbedding.value}}::vector) > 0.75
11order by similarity desc
12-- match count set to 5, you can change it
13limit 5;
14You can tweak both the match threshold and the match count to your liking.
Note that the queryEmbedding is being cast to vector (::vector) on the Postgres side. Retool doesn't fully support Postgres vectors just yet, so we're going to pass the database vectors as strings and have Postgres cast the vectors into the right type.
Set this query to Run query automatically when inputs change.
Now, create a new query using the OpenAI adapter. This will take the search input and turn it into an embedding, using the same functionality you used earlier to generate embeddings for your GitHub pull requests:
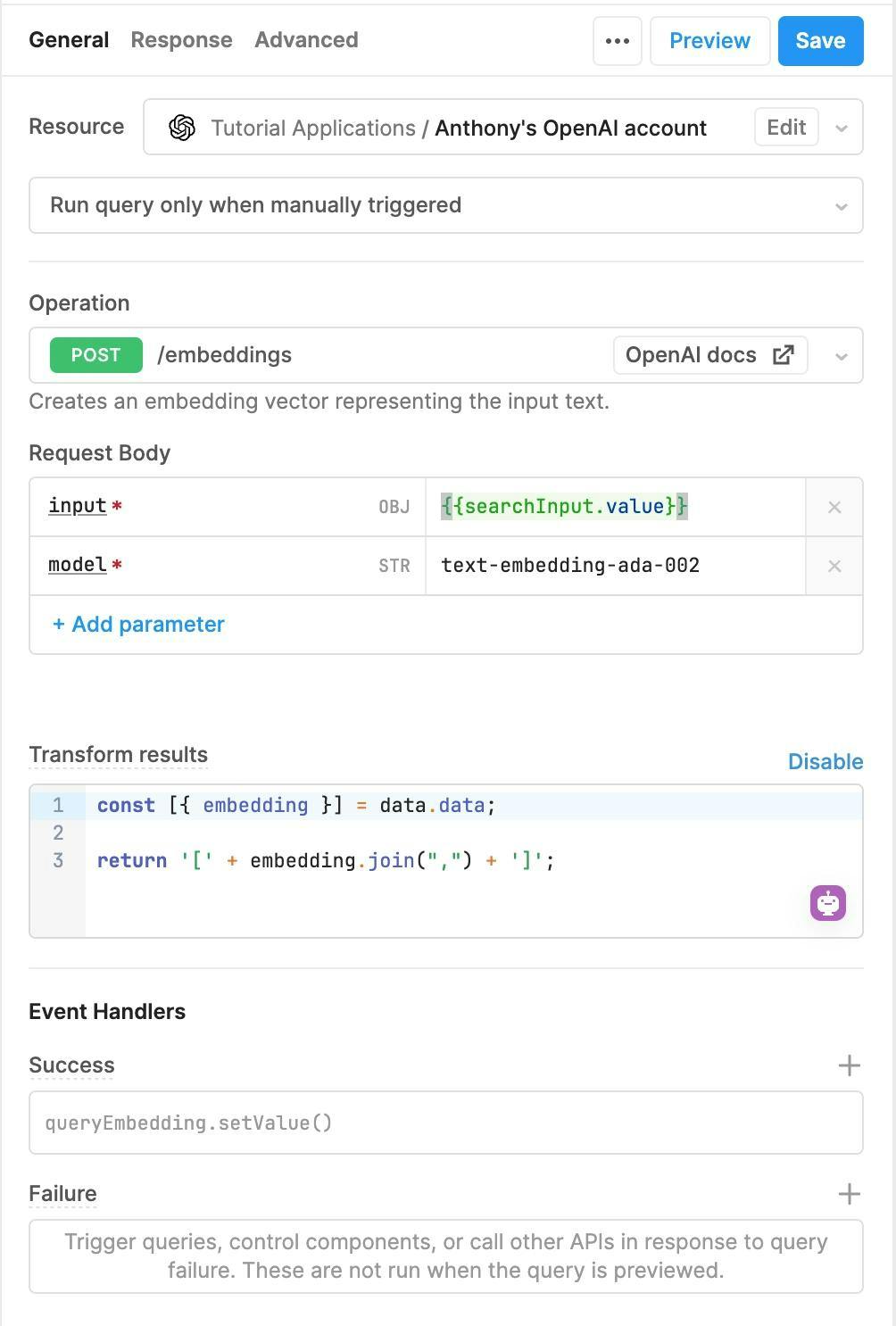
In Request Body, set the input to the value of the search field in your app.
In Transform results, you need to convert the array of floats into a string literal. So, convert it to a string, and the searchPRs query will turn the string into a vector in the database (::vector).
Finally, add an Event Handler. Set the value of the queryEmbedding variable to the output of this query.
With these queries in place, your app is wired up and ready to go!
Once you get a taste of embeddings, it's hard to go back to search that's restricted to only literal matches. Between commits, pull requests, and issues, there's a lot to sift through when you're looking for something specific. Embeddings can help you find precisely what you want without being precise.
But search is only one way you can use embeddings to build tooling on top of your GitHub data. You can also use embeddings to perform analysis on code that's been committed, like the ratio of bugs to new features. Or to surface the most critical-seeming commits and PRs that have been pushed in the last few days.
Personally, I’m super excited about all the potential embeddings unlock for developers. And I’m equally excited about how quickly you can build apps on top of data from the most important tools in your stack by using Sequin and Retool. If you’re curious about other ways to leverage embeddings or how to make them work for your use case, get in touch—I’m @acco in the Retool Discourse community. I’d love to hear what you’re building and answer any questions about building LLM-powered tools on top of API data!

